1. How to train your MAML
Source: https://arxiv.org/pdf/1810.09502.pdf
Authors: Antreas Antoniou, Amos Storkey, Harrison Edwards
Topics: meta learning, few-shot learning
Model Agnostic Meta Learning (MAML) (Finn et al. 2017) is an elegantly simple meta-learning algorithm yet produces state-of-the-art results in few-shot learning problems.
MAML is also general enough in the sense that it can be applied on any gradient-based algorithms.
In short, the way that MAML works is to provide good initialization parameters for a model such that after a few steps of standard training on a few-shot task, the model will perform well on that task.
Few-shot learning is concerned with constructing a good ML model trained from a few examples.
A successful few-shot learning will be very useful in the context of supervised learning as it will reduce a huge amount of effort in annotating the training examples.
Despite its success, some technical problems in MAML that may hinder its true potential remain unsolved.
This paper investigates the problems such as training instability, absence of batch normalization statistic accumulation, non-optimal generalization and convergence speed due to fixed learning rate, etc, and proposes solutions to those problems.
The resulting algorithm, referred to as MAML++, was evaluated on the Omniglot and Mini-Imagenet datasets.
The outcomes show some superiorities of MAML++ over MAML both in stability and generalization performance.
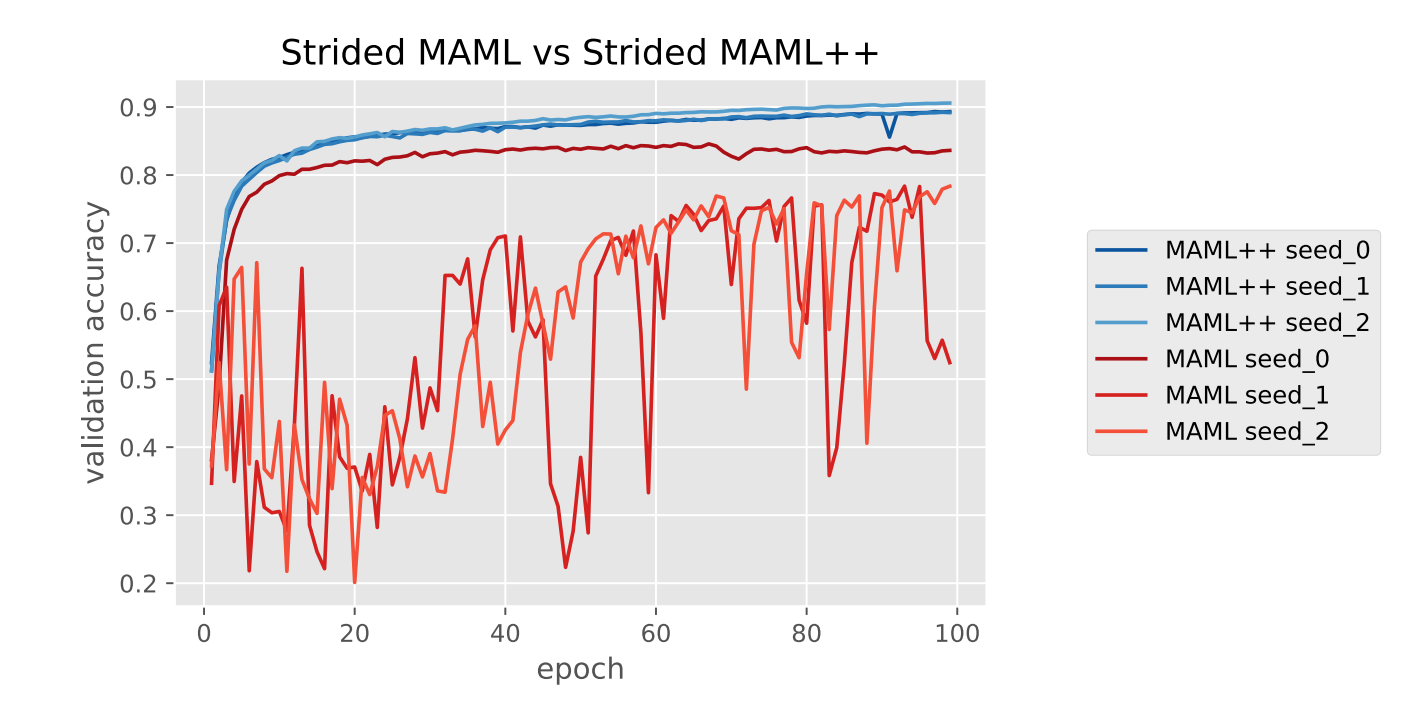
Comparison between MAML vs MAML++
2. Data-efficient image recognition with contrastive predictive coding
Source: https://arxiv.org/pdf/1905.09272.pdf
Authors : Olivier J. Henaff, Ali Razavi, Carl Doersch, S. M. Ali Eslami, Aaron van der Oord
Topics: computer vision, semi-supervised deep learning
Biological vision is thought to leverage vast amounts of unlabeled data to perform self-supervised learning as a prior to support object classification tasks with limited supervision.
Computer vision has so far not quite succeeded in mimicing such the mechanism.
The most successful image classifier is built upon deep learning that is typically label-hungry.
It is desirable to have a system that can be trained on a small amount of labeled data.
This paper handles the small-label challenge by adapting a recent self-supervised learning algorithm called Contrastive Predictive Coding (CPC) (van den Oord et al. 2018) with an unusually deep and wide residual network, layer normalization rather than batch normalization, and predicting both lower- and higher-level features.
The pretrained network is then used to extract deep representations as inputs to a standard linear classifier.
From the evaluation on ImageNet dataset, this strategy outperforms AlexNet model that is trained with full supervision, with 61% Top-1 and 83% Top-5 accuracies – AlexNet’s accuracies are 59.3% Top-1 and 81.8% Top-5, respectively).
When given a small number of labeled images (as few as 13 labels per class), this model retrains a strong classification performance, surpassing state-of-the-art semi-supervised methods by 10% Top-5 accuracy and supervised methods by 20%.
Learning from a small data is a limitation for deep learning, which is typically label-hungry.
This work opens a new regime in tasks of which only a few labels are available such as detecting rare diseases, spotting defects in a retail pipeline, detecting anomalies/unusual actions in video surveillance, etc.
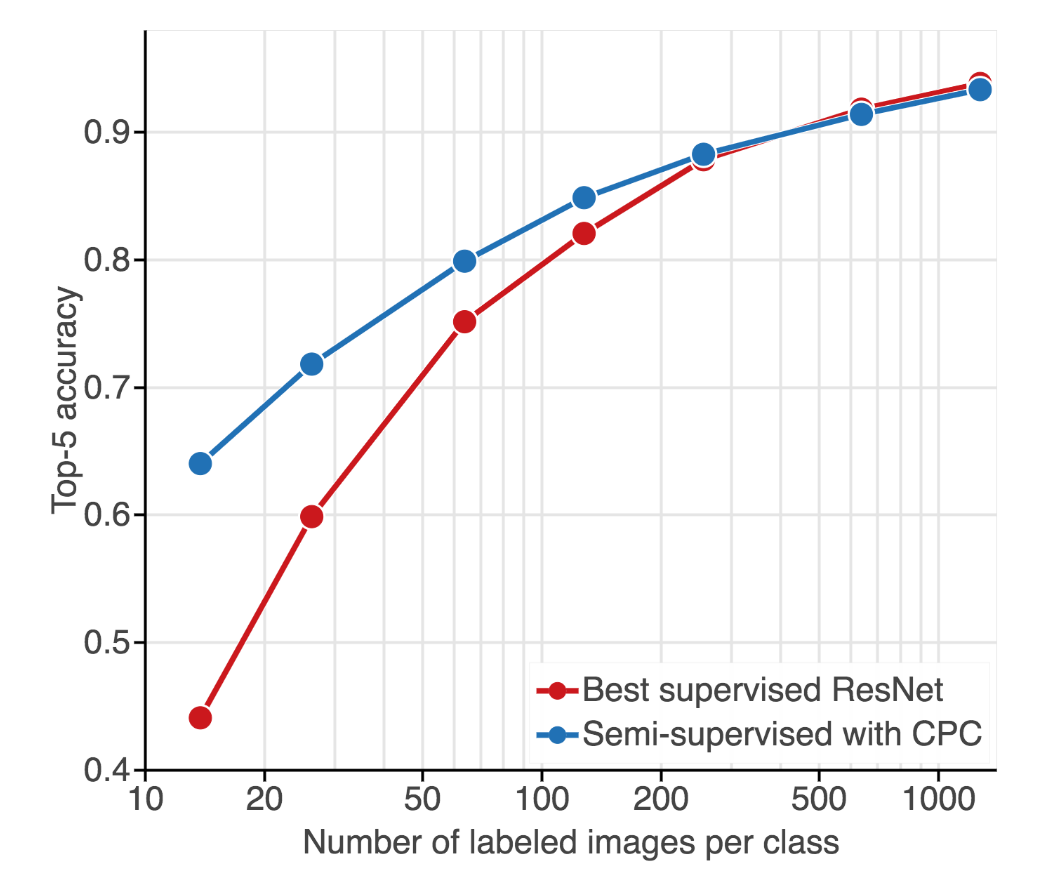
Classification accuracy comparison between self-supervision with CPC and fully supervised ResNet as a function of the number of labeled examples.
3. Understanding convolutional neural networks for text classification
Source: https://www.aclweb.org/anthology/W18-5408
Authors: Alon Jacovi, Oren Sar Shalom, Yoav Goldberg
Topics: deep learning, NLP
This paper investigates the interpretability of convolutional networks that are trained for text classification.
Interpretablity is about presenting a structured explanation which captures what an ML model has learned, which is important to increase trust in model predictions, analyze errors or improve the model (Riberio et al. 2016).
There have been a number of works that address the interpretability of deep learning models on NLP tasks.
However, this area is still generally under-explored, particularly in comparison to computer vision tasks.
Furthermore, the proposed methods for interpreting computer vision models may not be directly applicable for NLP models.
A common wisdom in terms of 1D-CNN applied on texts is that convolutional filters followed by global max-pooling serve as ngram detectors.
This work identifies and refines current intuitions as to how 1D-CNNs work on text domain.
Some key takeaways are as follows:
- Max-pooling induces a thresholding behaviour, and values below a given threshold are ignored when making a prediction.
- Filters are not homogeneous, i.e., a single filter can, and often does, detect multiple distinctly different families of ngrams.
- Filters also detect negative items in ngrams.