1. Neural Factorization Machines for Sparse Predictive Analytics
Source: https://arxiv.org/pdf/1708.05027.pdf
Authors: Xiangnan He, Tat-Seng Chua
Topics: recommender system, neural networks
Paper ini mengajukan sebuah model recommender system yang dinamakan Neural Factorization Machines (NFM).
Model ini merupakan modifikasi atau perbaikan dari Factorization Machines (FM) yang sebelumnya sudah cukup populer dan aplikatif pada recommender system.
Untuk memahami NFM, pertama-tama diperlukan pemahaman akan FM.
FM merupakan sebuah model prediktif linear sebagaimana halnya linear regression atau linear SVM, dengan tambahan komponen interaksi antar atribut-atribut dari input.
Adanya interaksi antar atribut tersebut membuat FM dikategorikan sebagai metode collaborative filtering.
Katakanlah \(\mathbf{x} \in \mathbb{R}^n\) merupakan input dari FM yang biasa disebut sebagai feature vector, dimana \(x_1, \ldots, x_n\) merupakan atribut-atribut dari input.
Dalam konteks recommender system, misalnya pada e-commerce, atribut-atribut tersebut dapat berupa informasi tentang pengguna, barang-barang yang dijual, waktu transaksi, ataupun informasi-informasi implisit lainnya.
Model FM didefinisikan sebagai berikut:
\[\begin{equation}
y_{FM} = w_0 + \sum_{i=1}^n w_i x_i + \sum_{i=1}^n \sum_{j=i+1}^n \langle \mathbf{v}_i, \mathbf{v}_j\rangle x_i x_j
\end{equation}\]
dimana \(y_{FM} \in \mathbb{R}\) merupakan skor prediksi yang dapat merepresentasikan apapun, seperti rating yang diberikan pengguna terhadap barang tertentu.
Gambar di bawah ini mengilustrasikan input (feature vectors) dan output dari FM:
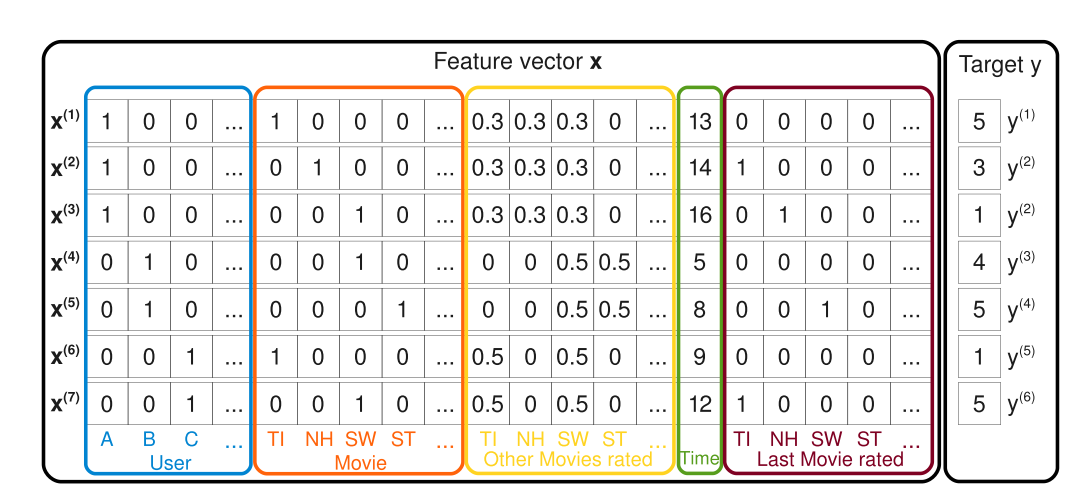
Gambar 1: Features atau representasi input dari FM (Rendle 2010)
FM cukup sukses diimplementasikan untuk berbagai aplikasi recommender system dan cocok untuk problem dengan karakteristik feature vectors yang angka 0-nya mendominasi (dikenal dengan istilah sparse).
Namun demikian, FM pada esensinya merupakan model linear sehingga akan kesulitan mempelajari data yang kompleks dan memiliki struktur non-linear.
NFM memasukkan unsur non-linear pada FM dengan memanfaatkan neural networks untuk memodelkan interaksi antar atribut input.
Persamaan model NFM mirip dengan FM, yaitu:
\[\begin{equation}
y_{NFM} = w_0 + \sum_{i=1}^n w_i x_i + \sum_{i=1}^n \sum_{j=i+1}^n f(\mathbf{x})
\end{equation}\]
dimana fungsi \(f: \mathbb{R}^n \rightarrow \mathbb{R}\) merupakan sebuah neural network.
Arsitektur dari neural network tersebut digambarkan sebagai berikut:
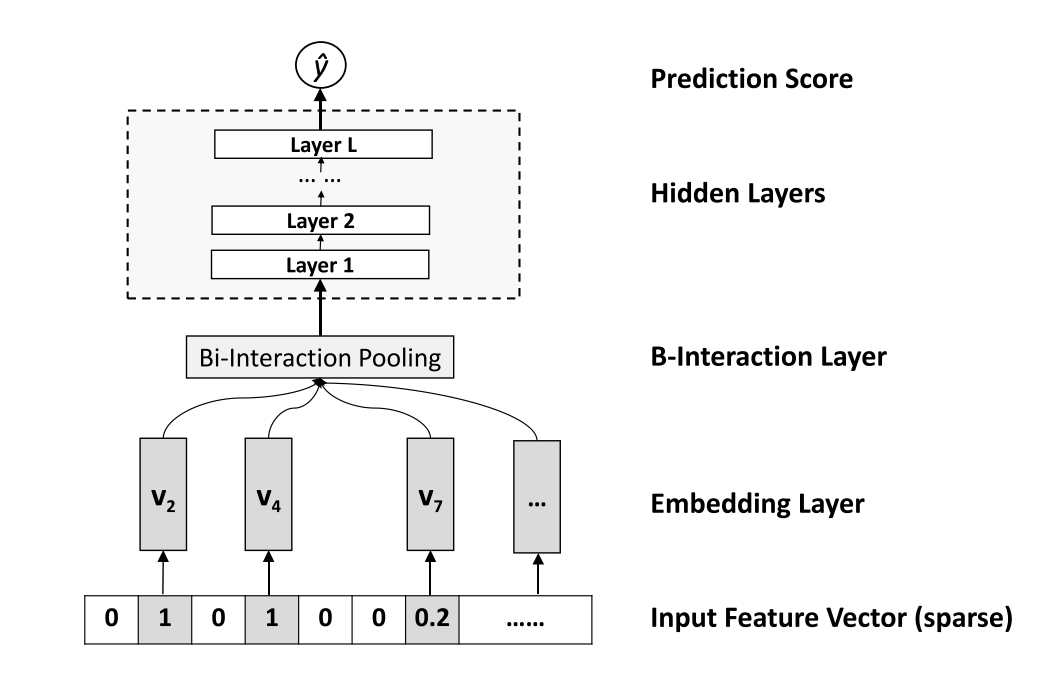
Gambar 2: Arsitektur neural networks pada NFM (He and Chua 2017)
Pada model tersebut terdapat layer khusus yang dinamakan bi-interaction layer yang merekapitulasi interaksi dari semua atribut input menjadi sebuah vektor.
Hasil eksperimen pada 2 domain recommender systems: Frappe dan MovieLens, menunjukkan efektifitas dari NFM.
NFM bekerja lebih baik daripada FM dengan peningkatan performa relatif sebesar \(7.5 \%\).
Dibandingkan dengan metode sistem rekomendasi berbasis deep learning seperti Wide&Deep dan DeepCross, NFM juga bekerja sedikit lebih baik pada 2 domain tersebut.
Keuntungan NFM lainnya adalah arsitekturnya yang notabene shallow sehingga memiliki jumlah parameter yang lebih sedikit dibandingkan Wide&Deep maupun DeepCross – yang berarti lebih sedikit membutuhkan memori penyimpanan dan lebih cepat untuk dieksekusi.
2. Language Models as Knowledge Bases?
Source: https://arxiv.org/pdf/1909.01066.pdf
Authors: Fabio Petroni, Tim Rocktaschel, Patrick Lewis, Anton Bakhtin, Yuxiang Wu, Alexander H. Miller, Sebastian Riedel
Topics: natural language processing, knowledge bases
Sekitar 2 tahun belakangan ini terjadi perkembangan yang pesat pada model bahasa generik yang dilatih secara self-supervised dengan menggunakan korpus berskala besar.
Model generik tersebut dapat digunakan dalam melakukan transfer learning: model yang sudah dilatih kemudian digunakan kembali untuk melakukan pekerjaan lainnya yang tidak harus berhubungan langsung dengan apa yang dipelajari di awal – model semacam ini dikenal dengan istilah pretrained model.
Beberapa contoh dari pretrained model tersebut antara lain ELMo, BERT, dan Open-GPT.
Model-model ini sangat sukses ketika ditransfer untuk menyelesaikan problem-problem NLP seperti text classification, textual entailment, semantic similarity, question answering, reading comprehension, dan sebagainya.
Artikel ini menjelaskan penelitian ke arah mengapa pretrained model tersebut memiliki performa yang sangat baik.
Dari berbagai observasi ditemukan bahwa model-model tersebut mampu melakukan tugas semacam melengkapi kata / teks yang hilang, mengindikasikan adanya informasi relasional yang berhasil dipelajari, semacam (subject, relation, object).
Adanya pengetahuan tersebut memungkinkan untuk melakukan query seperti (Dante, born-in, X), yaitu mencari fakta tentang X, yang biasanya dapat dilakukan dengan menggunakan knowledge base (KB) – diilustrasikan pada Gambar 2 di bawah ini.
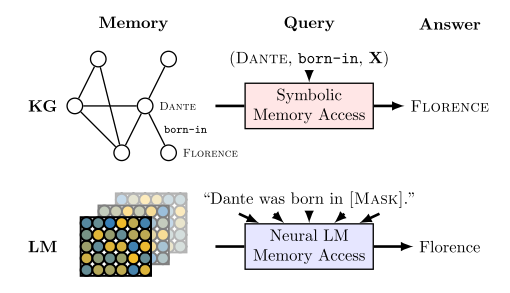
Gambar 2: Arsitektur neural networks pada NFM (Petroni et al. 2019)
Jika benar bahwa model bahasa generik memiliki karakteristik tersebut, maka ini akan memberikan berbagai keuntungan dibandingkan knowledge base konvensional yang biasanya memerlukan pipeline NLP yang rumit untuk mengkonstruksi pengetahuan di dalamnya, seperti entity extraction, coreference resolution, entity linking, dan relation extraction.
Model bahasa generik tidak memerlukan schema engineering dan anotasi data secara manual (karena tidak memerlukan supervised learning).
Penelitian ini fokus pada investigasi model BERT.
Dari hasil eksperimen empiris disimpulkan bahwa BERT memiliki pengetahuan relasional yang cukup komprehensif sebagaimana pada knowledge base tradisional.
BERT juga memiliki kemampuan memulihkan informasi faktual dan commonsense reasoning yang sangat baik, melebihi model-model bahasa generik lainnya.
Berikut beberapa contoh reasoning yang dihasilkan oleh BERT dari berbagai query yang sifatnya relasional:

Tabel 1: Keluaran dari model BERT saat diberikan query relasional