1. Direct speech-to-speech translation with a sequence-to-sequence model
Source: https://arxiv.org/pdf/1904.06037.pdf
Topics: speech-to-speech translation, sequence-to-sequence model, deep learning
Models that translate between spoken languages typically take an intermediate step, i.e., source speech –> source text –> translated text –> translated speech.
This paper proposes Translatotron, an end-to-end speech translation model that skips the step of converting the speech into text.
This implies an advantage in terms of lower inference latency since only 1 decoding step is needed, instead of 3.
Translatotron is not only translating but also reproducing the speaker’s voice on the translated speech.
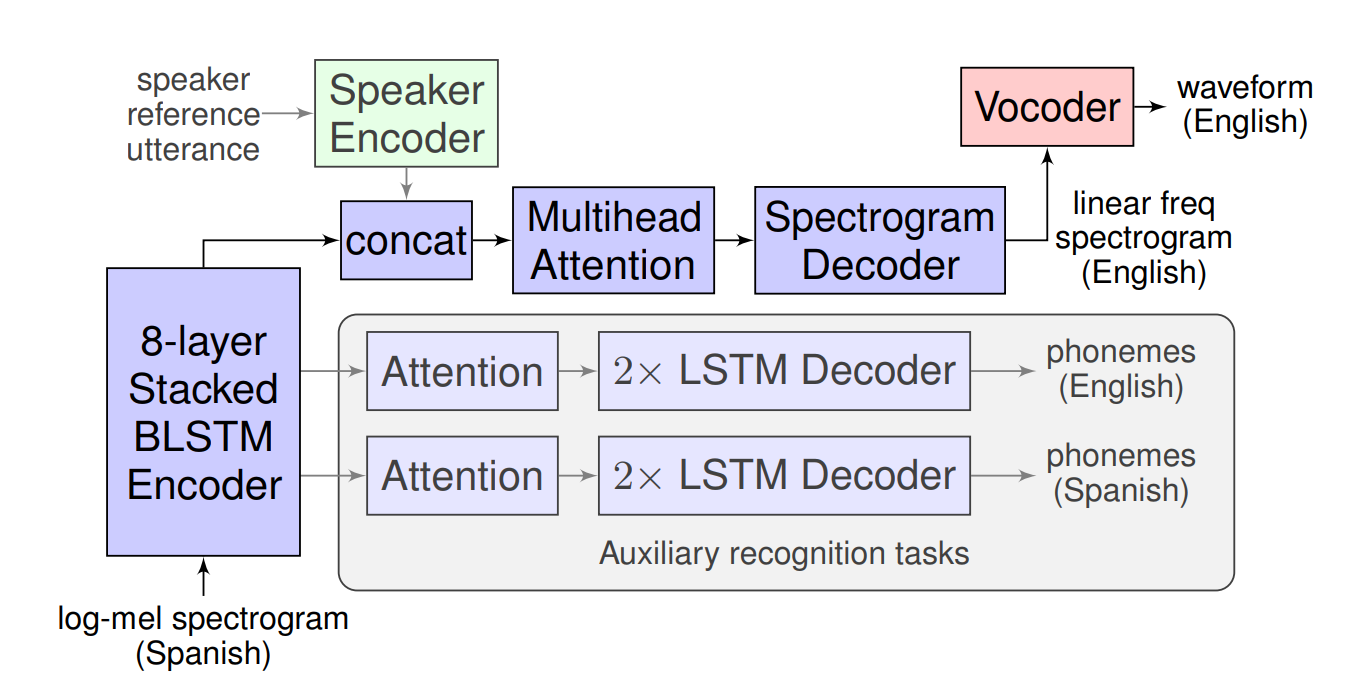
Model architecture of Translatotron
Translatotron has 3 main components:
- Attention-based sequence-to-sequence neural net: taking spectograms as input and generates spectograms in the translated language
- Neural vocoder: converting the output spectograms into audio wave.
- Pre-trained speaker encoder: preserving the characteristic of the speaker’s voice
The experiments show the effectiveness of Translatotron, trained on a large corpus of matched spoken phrases in Spanish and English, as well as phoneme transcripts.
The detailed results can be found at https://google-research.github.io/lingvo-lab/translatotron/.
In general, Translatotron slightly underperforms a baseline model with the intermediate text encoding-decoding steps in translating Spanish to English languages.
But it produces more realistic audio than pervious systems and breaks new ground for the end-to-end approach.

Source: https://arxiv.org/pdf/1703.03400.pdf
Topics: meta learning, learning to learn
One of the hallmarks of human intelligence is to learn quickly only from a few examples and adapt seamlessly as more data become available.
An attempt to manifest that characteristic into machine intelligence is through meta-learning, i.e., learning from metadata to change certain aspects of a learning algorithm or the learning method itself.
The aim of meta-learing is to automate human design decisions and revisit/optimize those decisions dynamically according to experience obtained during learning.
This paper proposes Model-Agnostic Meta-Learning (MAML) algorithm that initializes the gradient-based model’s parameters through meta-learning in such a way that the model can quickly adapt to a new task using only a few datapoints and training iterations.
“Model-agnostic” means that the algorithm can be directly applied to any learning algorithm trained with gradient descent – the paper shows
that MAML is applicable to fully connected, convolutional, or recurrent neural nets.
Furthermore, it can serve to solve a variety of tasks such as supervised classifications, regressions, and reinforcement learning.
The overall MAML algorithm is quite simple as described by the pseudo-code below.
MAML algorithm
The intuition behind MAML is that some internal representations are general-purpose, i.e., more transferrable to other tasks than others.
The MAML algorithm encourages the emergence of such representations by taking into account several tasks simultaneously in updating the model’s parameters.
3. Lessons learned turning machine learning models into real products and services
Source: https://www.oreilly.com/ideas/lessons-learned-turning-machine-learning-models-into-real-products-and-services
Topics: practical AI, business
This article highlights that there is a major difference between building machine learning models and actually deploying them into production as real, reliable, scalable, and scure products and services.
The first is something that is already a common practice which has been thought in schools or data science bootcamps – any junior data scientist or developer can do it with a good set of training data and the right tools.
The latter is fairly new, emerging domain, i.e., has not been well-taught in earlier phases of education, but important to guarantee successful AI applications in an organization.
If it is not executed well, the end result is a bottleneck where AI models fail to be turned into revenue-generating products and services.
The author mentioned a few aspects that need careful considerations before implementing a machine learning solution:
-
Models degrade in accuracy as soon as they are put in production
In real scenario, static ML models will very likely suffer from concept drift: the predictions offered by the models become less accurate as time goes on, since the production environment is dynamic.
The biggest mistake that could be made by us is taking care ML models like any other type of software or apps – once it’s built and live, we assume it will continue working as normal.
Organizations need to recognize that there is never a final version of a machine learning model.
It will constantly need to be fed by new data and updated over time.
-
Model localization
Typical machine learning models are designed to be domain-specific.
The exact same model that works for one geographical location (demographics, languages, tastes, etc) or group of audiences might not work for another.
For this reason, organizations need to have a deep understanding of the data and assumptions that are used to build the models and adjust them as needed.
-
Real “modeling” work starts in production
In production stage, there is a chance that we need to do remodeling of the AI solution.
This is due to that we cannot measure the actual expectation of the prediction performance until a model gets deployed.
The training data collected for initial modeling are usually not sufficient to handle the real cases.
As more and more customers begin to use an ML product or service, we can take advantage from customers’ feedback and their real-world data to improve the servie. This sometimes needs remodeling the initial solution to fit upon the new data.
-
Tools exist to help deploy, measure, and secure models
There are already a number of tools to help AI deployment, prediction measurement, and security that can be utilized.
These allow one organization for not building in-house AI production pipeline from scratch.
A thing that is worth considering is the pricing.
Most of these platforms are ither cloud-based or priced per usage, which can make it expensive to scale or build independent in-house capability.
For this reason, companies should look for a machine learning platform that includes full source code, unlimited commercial use, and turnkey implementation.
Make sure to avoid vendor lock-in or external dependency that may hinder further improvements.